> For the complete documentation index, see [llms.txt](https://knowledge.illumina.com/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://knowledge.illumina.com/software/general/software-general-reference_material-list/000007412.md).
# FASTQ文件解读
\
Illumina测序技术使用 [簇生成和边合成边测序(SBS)化学技术](https://v.youku.com/v_show/id_XMzMxMTk0NzQ5Ng==.html?spm=a2h3j.8428770.3416059.1)对流动槽(flow cell)上数百万或数十亿簇(cluster)进行测序,具体簇的数目取决于测序平台。 在边合成边测序化学过程中,仪器上的实时分析(RTA)软件对每个簇的每个循环进行碱基检出和存储。 RTA以单个读取碱基(base call,或称BCL)文件的形式存储碱基检出数据。 测序完成后,必须将BCL文件中的测定的碱基转换为序列数据。 此过程称为BCL到FASTQ的转换。
FASTQ文件是一个文本文件,其中包含通过流动槽(flow cell)上质控参数的簇(cluster)的测序数据(有关簇的质控参数,请参阅本公告的“其他信息”部分)。如果样本是[multiplexed](http://www.illumina.com/technology/next-generation-sequencing/multiplexing-sequencing-assay.html),则FASTQ文件生成的第一步是*demultiplexing*。 *demultiplexing*根据簇的[index](http://support.illumina.com/downloads/indexed-sequencing-overview-15057455.html)序列将簇分配给样本。 *demultiplexing*后,将每个样本的组合序列写入FASTQ文件。 如果未对样品进行multiplex,则不会发生*demultiplexing*,并且对于每个流动槽每个通道(Lane)中的所有簇都分配给一个样品。
对于单端测序的运行,将为每个流动槽上每条通道的每个样品创建一个Read 1(R1)FASTQ文件。 对于双端测序的运行,将为每个流动槽上每条通道的每个样品各创建一个R1和一个Read 2(R2)FASTQ文件。 FASTQ文件是使用扩展名\*.fastq.gz压缩和创建的。
**FASTQ文件是什么样的?**
对于每个通过质控参数的簇,一个序列被写入相应样本的R1 FASTQ文件,而对于双端测序运行,另外一个序列也被写入该样本的R2 FASTQ文件。 FASTQ文件中的每个条目包含4行:
1. 序列标识符,其中包含有关测序运行和簇的信息。 该行的具体内容会因使用的BCL到FASTQ转换软件而不同。
2. 序列(碱基信号; A,C,T,G和N)。
3. 分隔符,只是一个加号(+)。
4. 读取碱基的[质量值](https://sapac.support.illumina.com/content/illumina-marketing/en/science/technology/next-generation-sequencing/plan-experiments/quality-scores.html)。T这些是Phred +33编码的,使用 [ASCII](http://drive5.com/usearch/manual/quality_score.html)字符表示数字质量值。
这是R1 FASTQ文件中单个记录条目的示例:
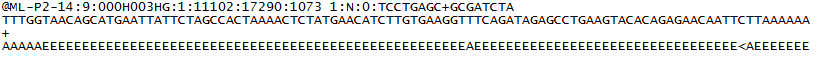
有关FASTQ [格式](https://sapac.support.illumina.com/content/illumina-marketing/en/informatics/sequencing-data-analysis/sequence-file-formats.html)的更多详细信息,请参见[此处](https://help.basespace.illumina.com/articles/descriptive/fastq-files/)。
**如何查看FASTQ文件**
FASTQ文件最多可以包含数百万个条目,大小可以为数兆字节或千兆字节,这常常使它们太大而无法在常规文本编辑器中打开。 通常情况下,并没有必要查看FASTQ文件,因为它们是做下游分析(例如与参考基因组序列比对或从头组装)的中间文件。
如果出于故障排除目的或兴趣需要查看FASTQ文件时,则需要在可以处理非常大文件的文本编辑器打开文件,或者使用可以通过命令行查看大文件的Unix或Linux系统。
**如何生成FASTQ文件**
FASTQ文件生成是MiSeq上[MiSeq Reporter](http://support.illumina.com/sequencing/sequencing_software/miseq_reporter.html)和MiniSeq上的[Local Run Manager](http://support.illumina.com/sequencing/sequencing_software/local-run-manager.html)进行所有分析工作流程的第一步。 分析完成后,FASTQ文件位于MiSeq上的< run folder > \ Data \ Intensities \ BaseCalls和MiniSeq上的< run folder > \ Alignment \_#\ <子文件夹> \ Fastq中。
对于上传到[BaseSpace基因云计算平台](https://basespace.illumina.com/)的所有运行,测序数据上传结束后会自动生成FASTQ文件,并且FASTQ文件可以用作BaseSpace基因云计算平台上[各种分析apps](http://www.illumina.com/informatics/research/sequencing-data-analysis-management/basespace/basespace-apps.html)的输入文件。 在BaseSpace基因云计算平台上,您可以在与您的运行关联的项目(projects)中找到FASTQ文件。
[bcl2fastq](http://support.illumina.com/sequencing/sequencing_software/bcl2fastq-conversion-software.html)转换软件可用于将目前所有Illumina测序系统上产生的数据转换成FASTQ文件。
有关在FASTQ文件生成过程中使用的不同设置的详细信息,请参阅下面的软件用户指南。
* [MiSeq Reporter](http://support.illumina.com/downloads/miseq-reporter-workflow-reference-guides.html)
* [Local Run Manager](http://support.illumina.com/sequencing/sequencing_software/local-run-manager/documentation.html)
* [bcl2fastq](http://support.illumina.com/sequencing/sequencing_software/bcl2fastq-conversion-software/documentation.html)
* [BCL Convert](http://support.illumina.com/sequencing/sequencing_software/bcl-convert/documentation.html)
**其他信息**
* 有关簇通过质控参数的说明和要求,请参阅[MiSeq: Imaging and Base Calling](https://support.illumina.com/content/dam/illumina-support/courses/MiSeq_Imaging_and_Base_Calling/story_html5.html) 课程的1.5.8节。
* 有关NovaSeq,NextSeq 500/550和MiniSeq系统上的碱基检出的更多信息,请参阅[2-Channel SBS Technology](https://www.illumina.com/technology/next-generation-sequencing/sequencing-technology/2-channel-sbs.html)。
* 有关在MiSeq和HiSeq系统上进行碱基检出的更多信息,请参见[Illumina Sequencing Technology](http://www.illumina.com/documents/products/techspotlights/techspotlight_sequencing.pdf)。
\
\
\
| |
| :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
| *For any feedback or questions regarding this article (Illumina Knowledge Article #7412), contact Illumina Technical Support* [*techsupport@illumina.com*](mailto:techsupport@illumina.com?subject=Question%2FFeedback%20Regarding%20Illumina%20Knowledge%20Article%20#000007412%20-%20Software%20\&body=Dear%20Illumina%20Technical%20Support,%0D%0A%0D%0A)*.* |
---
# Agent Instructions
This documentation is published with GitBook. GitBook is the documentation platform designed so that both humans and AI agents can read, navigate, and reason over technical content effectively. Learn more at gitbook.com.
## Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter, and the optional `goal` query parameter:
```
GET https://knowledge.illumina.com/software/general/software-general-reference_material-list/000007412.md?ask=&goal=
```
`ask` is the immediate question: it should be specific, self-contained, and written in natural language.
`goal` is optional and describes the broader end goal you are ultimately trying to accomplish on behalf of the user. GitBook uses it to tailor the answer towards what is most useful for that goal.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.