> For the complete documentation index, see [llms.txt](https://knowledge.illumina.com/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://knowledge.illumina.com/library-preparation/general/library-preparation-general-reference_material-list/000007309.md).
# 是否可以混合不同类型的文库并同时进行测序?
不同的文库工作流程可以产生大小、index长度、簇生成效率等方面不同的文库。Illumina建议混合使用相同文库制备工作流程制备的文库并进行测序。此建议适用于在同一运行中(没有单独通道可以加载文库的flow cell)或同一通道中(使用单独通道加载文库的flow cell)混合的库,原因如下:\
1\. **无法预测的簇密度和对测序质量的负面影响。**不同的文库类型可以有不同的片段长度,较短的文库相比较长的文库成簇效率更高。因此,相对于较长的文库,较短的文库将会过度表达(如图1),这有可能导致测序中簇密度过高。如果测序长度超过了较短文库的片段长度,测序质量就会受到负面影响。\
文库混合:50%长片段文库+50%短片段文库 ;flow cell上的簇,短片段文库过度表达
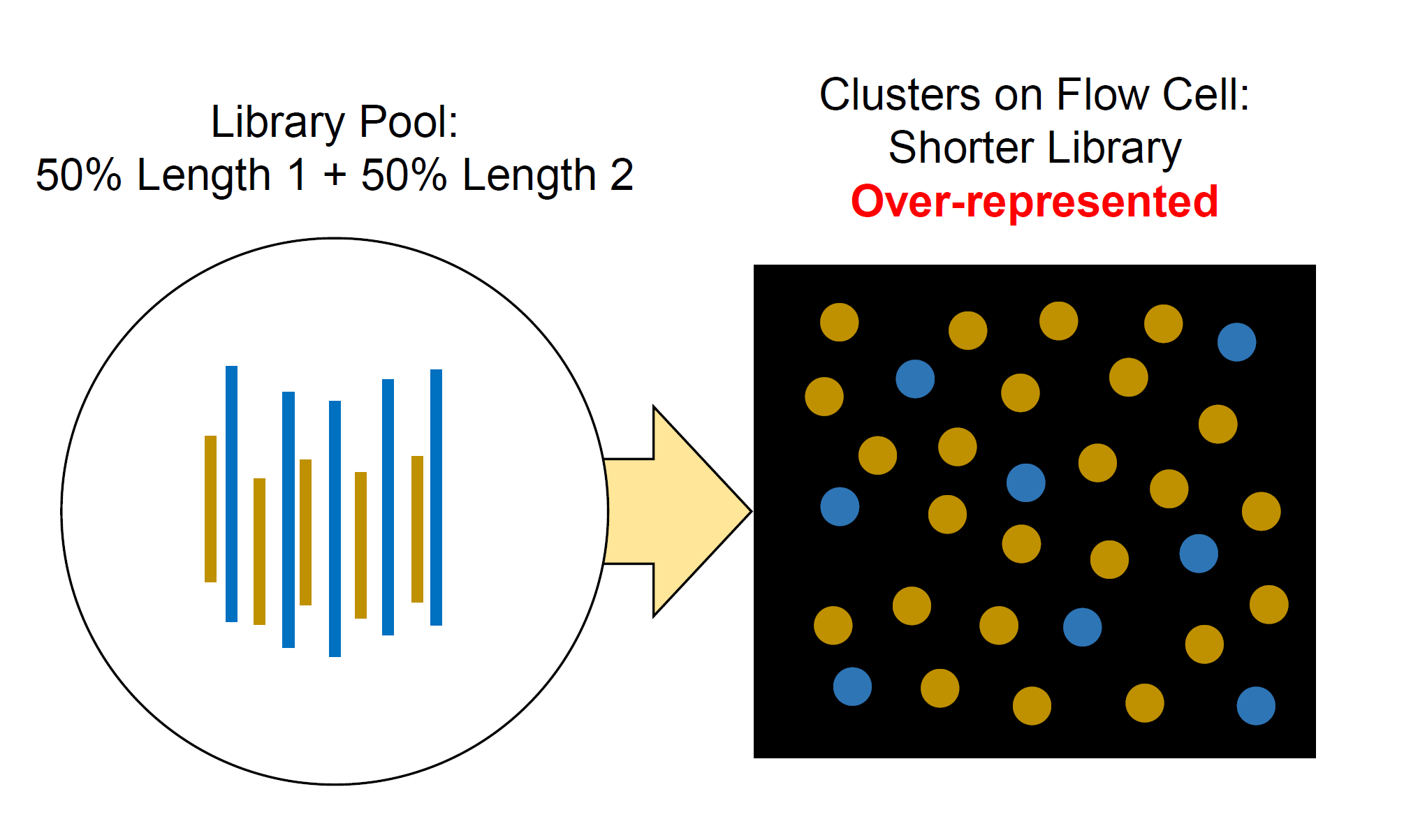
图1:同一个文库混合物中含有相同比例的两种不同长度的文库,这会导致较短片段文库的过度表达\
2\. **簇生成和数据输出不均匀。**即使片段大小相似,不同的文库类型会有不同的簇生成效率。这种差异会导致不可预知的簇生成/簇密度,并难以确定使用中的最佳上样浓度。Illumina建议运行单一的文库类型,并根据以下指南为特定的测序仪优化上样浓度:
[Clustering Optimization Overview Guide](https://support.illumina.com/downloads/cluster-optimization-overview-guide-1000000071511.html)
[如何在Illumina测序平台上获得更稳定的簇密度](https://knowledge.illumina.com/instrumentation/general/instrumentation-general-reference_material-list/000007398)
\
此外,不同的文库类型有不同的[测序深度/覆盖度要求](https://www.illumina.com/science/technology/next-generation-sequencing/plan-experiments/coverage.html)。例如,全基因组文库比扩增子文库需要更多的覆盖度(如图2)。不同文库类型的上样浓度必须进行优化,以实现准确的覆盖度水平,而Illumina并没有为这种优化提供指导。[覆盖度计算器](https://support.illumina.com/downloads/sequencing_coverage_calculator.html)可用于确定单一类型文库单次测序的上样数目。\
文库混合:50%类型A的文库+50%类型B的文库 ;Flow cell上的簇;读数解读
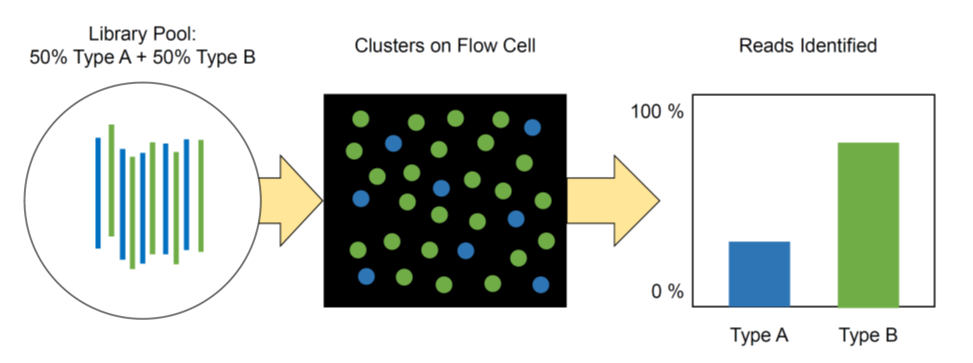
图2:如果一个文库混合物中含有等量的两种不同类型的文库,即使两种文库的片段长度相同,也可能会导致其中一种类型文库的比例过高,从而影响读数分布和覆盖度。\
3\. **困难且可能模糊的数据拆分。**不同的文库使用不同类型的index(例如,单index或者双index,和不同的index长度)。设置一个运行(或flow cell中每条通道可以单独加载文库)来读取或者单index或者双index,但不能同时检测单index和双index。当单index和双index文库混合时,i5或i7 index同时存在,将设置成单index读长配置(如图3)。

图3:红色的X表示文库混合物中未被读取的index的位置。绿色对勾√表示文库混合物中可以被读取的index的位置。在这个文库混合物中,仅单一的、6个碱基长度的index为可靠的读取结果,因为i7 index会被优先读取,这是为单index文库所作的index读取设置。这样的运行设置会对index拆分产生负面影响。\
总之,将不同类型的文库混合在同一测序运行中或同一通道中是不推荐的,需要进行独立的优化和验证。\
注意:可以将不同类型的文库加载到支持单独通道加样的flow cell,这样不同类型的文库可以加载到不同的通道上。[NovaSeq X Series instrument](https://www.illumina.com/systems/sequencing-platforms/novaseq-x-plus/specifications.html) 和 [NovaSeq Xp Workflow](https://www.illumina.com/content/illumina-marketing/amr/en_US/products/by-type/sequencing-kits/cluster-gen-sequencing-reagents/novaseq-xp.html)都支持单独通道加载。然而,即使有独立的flow cell 通道,一次测序运行只能使用一种读长配置。
\
\
\
| |
| :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
| *For any feedback or questions regarding this article (Illumina Knowledge Article #7309), contact Illumina Technical Support* [*techsupport@illumina.com*](mailto:techsupport@illumina.com?subject=Question%2FFeedback%20Regarding%20Illumina%20Knowledge%20Article%20#000007309%20-%20Library%20Preparation%20\&body=Dear%20Illumina%20Technical%20Support,%0D%0A%0D%0A)*.* |
---
# Agent Instructions
This documentation is published with GitBook. GitBook is the documentation platform designed so that both humans and AI agents can read, navigate, and reason over technical content effectively. Learn more at gitbook.com.
## Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter, and the optional `goal` query parameter:
```
GET https://knowledge.illumina.com/library-preparation/general/library-preparation-general-reference_material-list/000007309.md?ask=&goal=
```
`ask` is the immediate question: it should be specific, self-contained, and written in natural language.
`goal` is optional and describes the broader end goal you are ultimately trying to accomplish on behalf of the user. GitBook uses it to tailor the answer towards what is most useful for that goal.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.